Este artículo fue escrito por Mandeep Singh, analista senior de la industria de Bloomberg Intelligence, y el analista asociado Robert Biggar. Se publicó primero en la Terminal Bloomberg.
El cambio de la IA hacia la inferencia a escala a partir del desarrollo de modelos está inclinando la demanda de los centros de datos hacia las bases de datos (especialmente aquellas utilizadas por chatbots, agentes de codificación y otros agentes de IA) y alejándose de las cargas de trabajo de aplicaciones como la gestión de relaciones con los clientes, lo que beneficia a proveedores de software como Oracle y MongoDB. Las cargas de trabajo de entrega de contenidos y ciberseguridad deberían tener un crecimiento más rápido en los centros de datos de IA dado su papel en la implementación de agentes.
Los agentes de IA impulsan la demanda de centros de datos hacia la capa de datos.
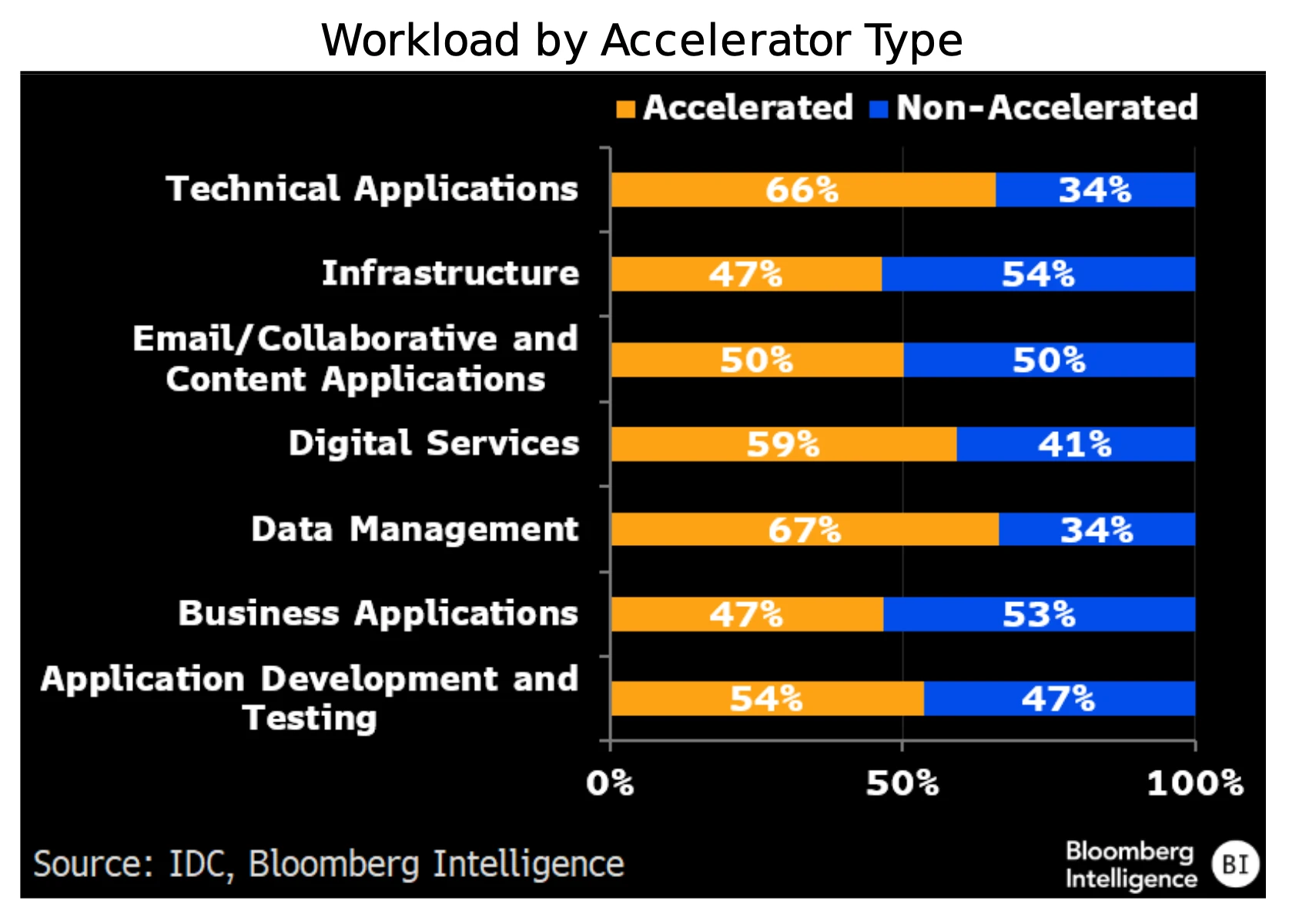
La tokenización de datos empresariales para alimentar chatbots, agentes de codificación y otros agentes de IA debería impulsar un crecimiento superior a la tendencia para las bases de datos vectoriales (almacenes de datos empresariales no estructurados). A medida que las funciones empresariales integran modelos de IA con datos corporativos propios, los proveedores de software como Oracle y MongoDB podrían experimentar una mayor demanda. Más allá del crecimiento en datos de capacitación, esperamos una inflexión en la creación de bases de datos y el consumo de datos a medida que se multiplican los agentes en distintos casos de uso.
Dada la intensa iteración que hay detrás de las capacidades avanzadas, las empresas se basarán en centros de datos abundantes de aceleradores para lograr un alto rendimiento de la carga de trabajo en la capa de la base de datos. Con la multiplicación de matrices en el centro de la inferencia de modelos en lenguaje de gran tamaño, las bases de datos vectoriales están posicionadas para estar entre las categorías de mayor carga de trabajo, lo que permite escalabilidad y respuestas más rápidas.
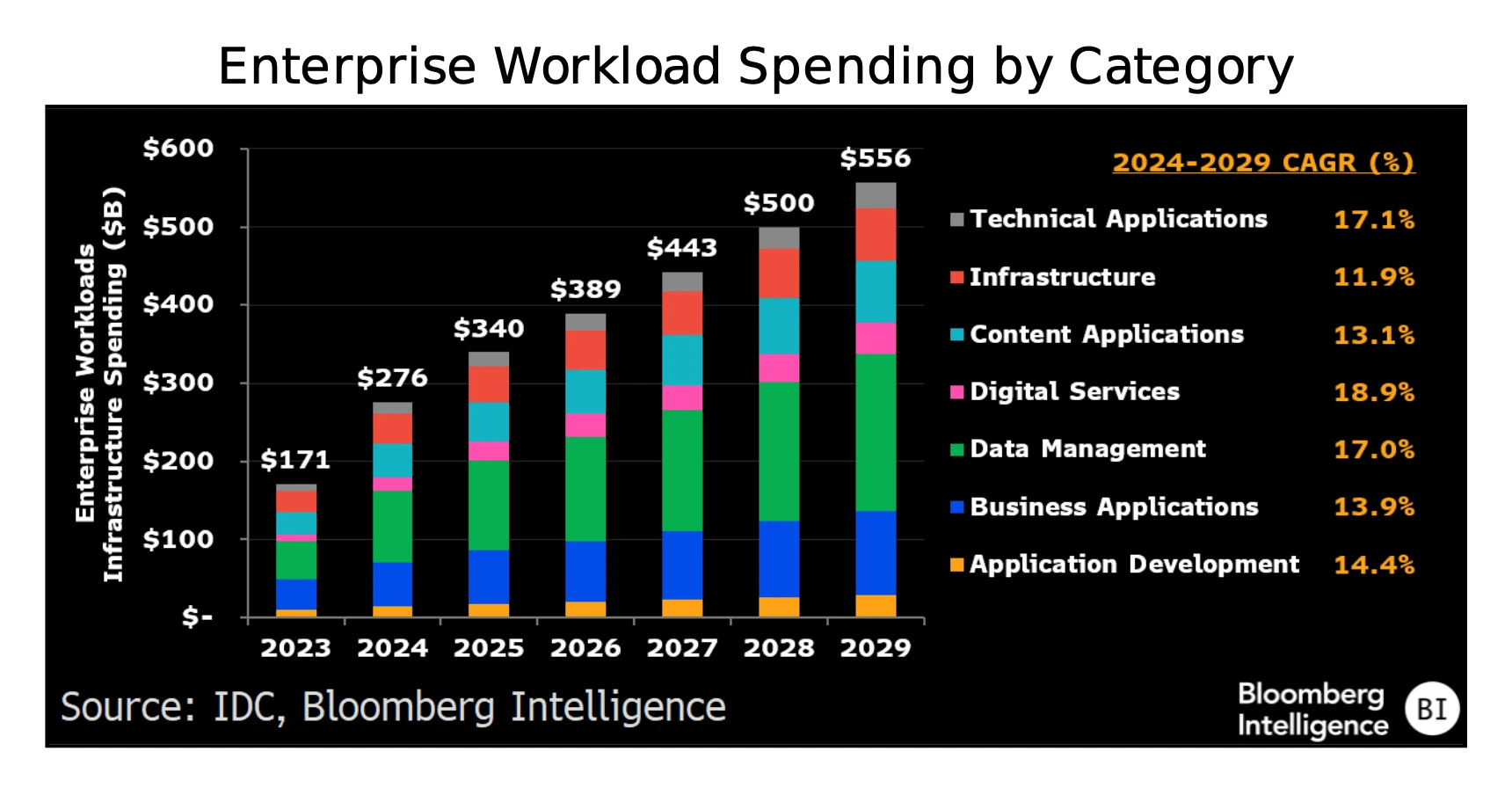
Se avecina una desaceleración en las cargas de trabajo de aplicaciones
A medida que los agentes de IA automatizan más pasos en los flujos de trabajo cotidianos, se necesita ejecutar menos de ese trabajo dentro de grandes conjuntos de aplicaciones. Esto apunta a un crecimiento más lento en la demanda de centros de datos para la planificación de recursos empresariales, la gestión de relaciones con los clientes, la gestión de capital humano y de la cadena de suministro. Los agentes de modelos de razonamiento y las herramientas de investigación profunda ahora pueden navegar por la web de forma autónoma, extraer fuentes y realizar análisis por sí mismos, tareas que antes se realizaban en las interfaces de usuario de esas aplicaciones.
El software de ingeniería (diseño y fabricación asistida por computadora), puede sortear estos obstáculos, ya que la simulación y la creación de datos sintéticos mantienen las cargas de trabajo ancladas en herramientas especializadas.
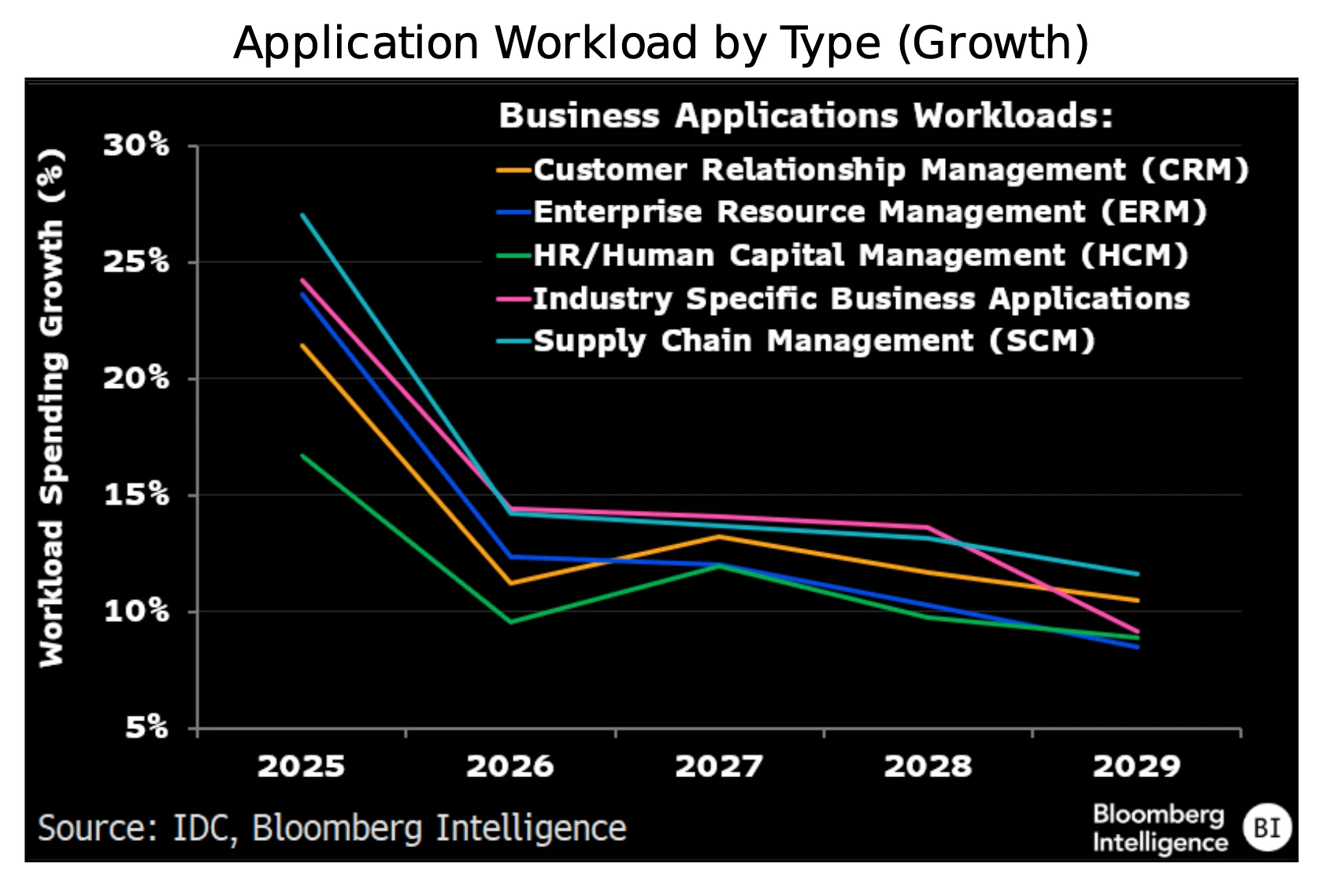
Los agentes de codificación potencian las cargas de trabajo de pruebas
Los agentes de codificación de IA —asistentes integrados en las herramientas de desarrollo que sugieren, escriben y corrigen código— deberían dar un gran impulso a las cargas de trabajo de desarrollo y prueba de aplicaciones. Los agentes de Cursor, Claude Code de Anthropic, GitHub Copilot, Codex de OpenAI y Gemini Code Assist manejan tareas como la depuración y la adición a código existente. Las empresas informan ganancias de productividad de un 30 a un 40% en el nuevo código escrito con estos agentes, lo que debería canalizar más desarrollo y pruebas a los centros de datos de IA. La generación de código basada en instrucciones se está convirtiendo rápidamente en una de las características de IA generativa más utilizadas en las aplicaciones empresariales existentes
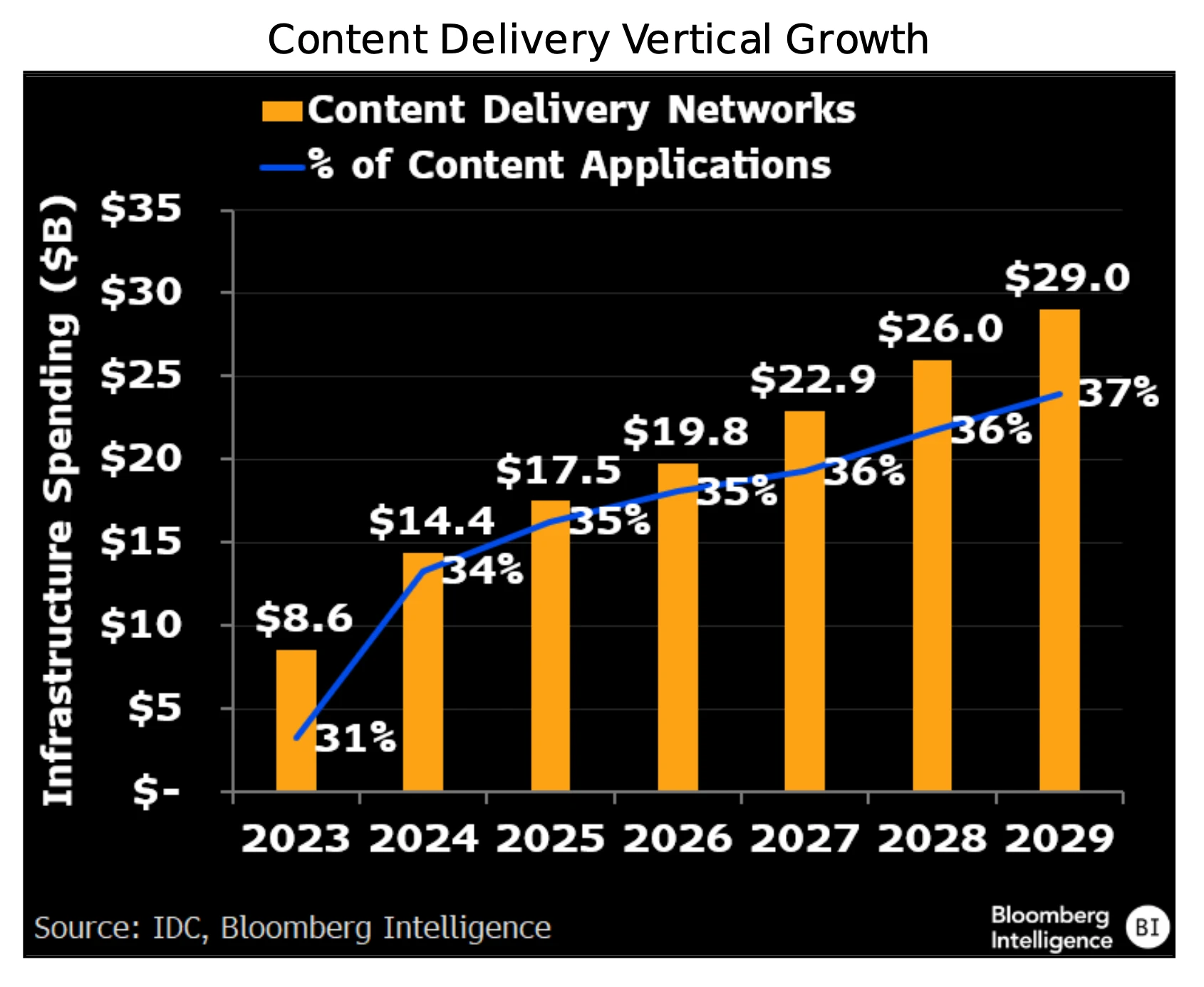
La entrega de contenidos y la ciberseguridad también se benefician
A medida que los agentes autónomos de IA se integren en los flujos de trabajo empresariales, más tareas críticas se ejecutarán en centros de datos de IA. El auge de modelos de razonamiento como o3 de OpenAI cambia el enfoque hacia garantizar que la infraestructura sea rápida, eficiente y confiable en lugar de simplemente tener un modelo. Esto supone un impulso para las redes de distribución de contenidos (CDN) de empresas como Cloudflare y proveedores de ciberseguridad como Zscaler. La mayoría de las empresas buscan integrar las bases de datos de conocimientos y documentación internas con LLM, al tiempo que confían en proveedores de CDN y ciberseguridad para gestionar el consumo de tokens para el ajuste y la inferencia de LLM.