Con 50,000 millones de parámetros de Bloomberg, BloombergGPT supera en gran medida a los modelos abiertos de tamaño similar en tareas financieras de PNL, sin comprometer el rendimiento en las pruebas de referencia generales de LLM.
Bloomberg publicó un documento de investigación en el que se detalla el desarrollo de BloombergGPT, un nuevo modelo de inteligencia artificial (IA) generativa a gran escala. Este modelo de lenguaje grande (LLM, por sus siglas en inglés) ha sido entrenado específicamente en una amplia gama de datos financieros para apoyar un conjunto diverso de tareas de procesamiento del lenguaje natural (NLP, en inglés) dentro de la industria financiera.
Los recientes avances en Inteligencia Artificial (IA) basada en LLM han demostrado nuevas y apasionantes aplicaciones para muchas áreas. Sin embargo, la complejidad y la terminología única del ámbito financiero justifican un modelo específico. BloombergGPT representa el primer paso en el desarrollo y aplicación de esta nueva tecnología para el sector financiero. Este modelo ayudará a Bloomberg a mejorar las tareas de PLN financiero existentes, como el análisis de sentimientos, el reconocimiento de entidades con nombre, la clasificación de noticias y la respuesta a preguntas, entre otras. Además, BloombergGPT abrirá nuevas oportunidades para aprovechar las enormes cantidades de datos disponibles en la Terminal de Bloomberg con el fin de ayudar mejor a los clientes de la empresa, aportando al mismo tiempo todo el potencial de la IA al ámbito financiero.
Durante más de una década, Bloomberg ha sido pionero en la aplicación de la IA, el aprendizaje automático y el PLN a las finanzas. En la actualidad, Bloomberg da soporte a un conjunto muy amplio y diverso de tareas de PLN que se beneficiarán de un nuevo modelo lingüístico que tiene en cuenta las finanzas. Los investigadores de Bloomberg son pioneros en un enfoque mixto que combina datos financieros con conjuntos de datos de uso general para entrenar un modelo que consigue los mejores resultados de su clase en las pruebas de referencia financieras, al tiempo que mantiene un rendimiento competitivo en las pruebas de referencia LLM de uso general.
Para lograr este hito, el grupo de investigación y productos de ML de Bloomberg colaboró con el equipo de ingeniería de IA de la empresa para construir uno de los mayores conjuntos de datos específicos de dominio hasta la fecha, aprovechando los recursos existentes de creación, recopilación y conservación de datos de la empresa. Como empresa de datos financieros, los analistas de datos de Bloomberg han recopilado y conservado documentos de lenguaje financiero a lo largo de cuarenta años. El equipo se basó en este extenso archivo de datos financieros para crear un amplio conjunto de datos de 363,000 millones de fichas de documentos financieros en inglés.
A estos datos se sumó otro conjunto de datos públicos, de 345,000 millones de tokens, para crear un gran corpus de entrenamiento con más de 700,000 millones de tokens. Utilizando una parte de este corpus de entrenamiento, el equipo entrenó un modelo de lenguaje causal con 50,000 millones de parámetros de decodificación. El modelo resultante se validó en pruebas de PNL específicas de finanzas, un conjunto de pruebas internas de Bloomberg y amplias categorías de tareas de PNL de propósito general de pruebas populares (por ejemplo, BIG-bench Hard, Knowledge Assessments, Reading Comprehension y Linguistic Tasks). En particular, el modelo BloombergGPT supera a los modelos existentes de tamaño similar en tareas financieras, al tiempo que sigue rindiendo a la par o mejor en pruebas de PNL generales.
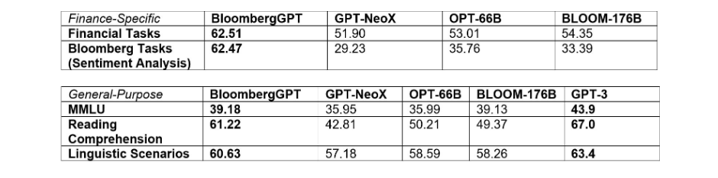 Tabla 1. Rendimiento de BloombergGPT en dos grandes categorías de tareas de PLN: específicas de finanzas y de uso general.
Tabla 1. Rendimiento de BloombergGPT en dos grandes categorías de tareas de PLN: específicas de finanzas y de uso general.
“Por todas las razones por las que los LLM generativos son atractivos -aprendizaje de pocos datos, generación de texto, sistemas conversacionales, etc. – vemos un enorme valor en haber desarrollado el primer LLM centrado en el ámbito financiero”, afirmó Shawn Edwards, CTO de Bloomberg. “BloombergGPT nos permitirá abordar muchos nuevos tipos de aplicaciones, al tiempo que ofrece un rendimiento mucho mayor de forma inmediata que los modelos personalizados para cada aplicación, con un tiempo de comercialización más rápido”.
“La calidad de los modelos de aprendizaje automático y PLN se reduce a los datos que se introducen en ellos”, explica Gideon Mann, Head del equipo de investigación y productos de ML de Bloomberg. “Gracias a la colección de documentos financieros que Bloomberg ha conservado durante cuatro décadas, hemos podido crear cuidadosamente un conjunto de datos amplio y limpio, específico del dominio, para entrenar un LLM que se adapte mejor a los casos de uso financiero. Estamos entusiasmados de utilizar BloombergGPT para mejorar los flujos de trabajo NLP existentes, mientras que también imaginamos nuevas formas de poner este modelo a trabajar para deleitar a nuestros clientes”.
Para más detalles sobre el desarrollo de BloombergGPT, lea el artículo en arXiv: https://arxiv.org/abs/2303.17564.
##