2023年3月30日
BloombergGPT在金融NLP任務表現大幅優於同等規模的其它開放模型,且無須犧牲一般基準的LLM表現
紐約—彭博於今日發佈了一篇研究論文,詳細介紹了BloombergGPTTM的開發,其為新型的大規模生成式人工智慧(AI)模型。這個大型語言模型(LLM)專門使用了大範圍的金融資料做訓練,來支援金融產業中的各種自然語言處理(NLP)任務。
以LLM為基礎的人工智慧(AI)近期的發展,已在許多領域展現了令人振奮的應用價值。然而,金融領域特有的複雜度與獨特語言,需要專為此領域設計的模型。BloombergGPT代表了這項新技術在金融業的開發與應用的第一步。此模型將協助彭博改善現有的金融NLP任務,例如:情緒分析、專有名詞辨識、新聞分類及問答等任務。此外,BloombergGPT將為在彭博終端機上提供的巨量資料開展新機會,以便為客戶提供更優質的協助,同時將AI的完整潛力注入金融領域。
十多年來,彭博一直是在金融業中應用AI、機器學習和NLP的先驅。而今,彭博支援非常龐大且多元的NLP任務集,且這些任務將獲益於新的使用金融資訊之語言模型。彭博研究人員開創了一種混合方法,將金融資料集與一般資料集結合,用以訓練在金融基準上達成同類最佳的模型,並且同時保有其在一般用途LLM基準的競爭力。
為了實現此里程碑,彭博的機器學習產品及研究(ML Product and Research)團隊與公司的AI工程師團隊合作,根據公司現有的資料建立、蒐集與篩選資源,構建了迄今為止最大的各類特定領域資料集之一。彭博作為一家金融數據公司,旗下的資料分析人員蒐集並維護了橫跨四十個年頭的財務語言文件。該團隊善用廣大的金融資料庫,建立了由英文金融文件所組成、廣納各種資訊的資料集,且包含了3630億個單詞(token)。
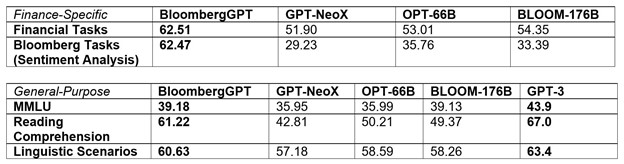
這些資料使用了來自公開資料集的3450億單詞並強化後,設立了一個包含超過7000億單詞的大型訓練語料庫。該團隊使用此訓練語料庫的一部份,訓練了一個包含500億參數、只使用解碼器(decoder-only)的因果語言模型。由此產生的模型,已通過現有金融領域NLP基準、一套彭博內部基準,和廣泛類別的熱門基準一般用途NLP任務(例如:BIG-bench Hard、知識評估、閱讀理解、語言任務)的驗證。值得注意的是,BloombergGPT模型在金融任務上的表現大幅領先現有的類似規模開放模型,尤其是在一般NLP基準上仍有相當甚至更佳的表現。
「生成型LLM有非常多吸引人的原因,包含:小樣本學習、文本生成、對話系統等等,因此,我們認為開發首個聚焦於金融領域的LLM非常具有價值。」彭博技術長Shawn Edwards先生表示,「BloombergGPT能讓我們處理新型態的應用功能,同時以開箱即用的特性,帶來比針對各應用程式客製化模型更高的效能,並能於更短時間推出。」
「機器學習與自然語言處理模型的品質,和放入這些模型中的資料有關,」彭博的機器學習產品及研究團隊負責人Gideon Mann先生說明道,「由於彭博公司已經蒐集了超過40年的金融文件,才讓我們能夠仔細地建立一個大型、乾淨、用於特定領域的資料集,用來訓練最適合金融領域使用情況的LLM。我們很高興能夠使用BloombergGPT來改進現有的NLP工作流程,同時也預見各種能為客戶提供價值的全新方式。」
關於BloombergGPT開發的更多詳細資訊,請於arXiv閱讀發表論文:https://arxiv.org/abs/2303.17564。
關於彭博
彭博是企業與金融資訊領域的全球領導者,提供可信賴的資料、新聞與見解,為市場帶來透明度、效率與公平性。該公司透過可靠的技術解決方案,串連全球金融生態系統中有影響力的社群,使我們的客戶能夠作出更明智的決策,並促進更好的協調合作。詳情請參考Bloomberg.com/company或申請示範說明。
媒體聯絡人
Chaim Haas
chaas30@bloomberg.net
Alyssa Gilmore
agilmore7@bloomberg.net