Bloomberg’s AI Engineering Group Publishes 4 NLP Research Papers at EMNLP 2023
December 08, 2023
During the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP 2023) in Singapore this week, researchers from Bloomberg’s AI Engineering Group are showcasing their expertise in natural language processing (NLP) by publishing four papers, one of which will appear in Findings of EMNLP 2023.
Through these papers, the authors and their collaborators highlight a variety of NLP applications, novel approaches and improved models used in key tasks, and other advances to the state-of-the-art in the field of computational linguistics.
We asked some of the authors to summarize their research and explain why the results were notable:
EntSUMv2: Data, Models and Evaluation for More Abstractive Entity-Centric Summarization
Dhruv Mehra (Bloomberg), Lingjue Xie (Bloomberg), Ella Hofmann-Coyle (Bloomberg), Mayank Kulkarni (work done while at Bloomberg) and Daniel Preoţiuc-Pietro (Bloomberg)
Poster Session 5 (Saturday, December 9, 2023 @ 11:00 AM SGT)


Please summarize your research. Why are your results notable?
Ella: Entity-centric summarization is a form of controllable summarization that requires producing a synopsis of a text document with respect to a specific entity. Our research focuses on abstractive summarization, which involves generating a new summary from scratch. This is in contrast to our previous work on extractive summarization, where the summary was constructed using only text that is present in the original text.
Exploration of this entity-centric summarization task was enabled by our past work at ACL 2022, where we introduced the EntSUM dataset. In this paper, we release the EntSUMv2 dataset, which builds upon the original EntSUM dataset to include new annotated abstractive summaries that are intentionally shortened to aid in generating more specific and useful entity-centric summaries.
In addition to releasing EntSUMv2, we explore supervised fine-tuning and instruction tuning of large language models to generate entity-specific abstractive summaries and perform evaluation against EntSUMv2.

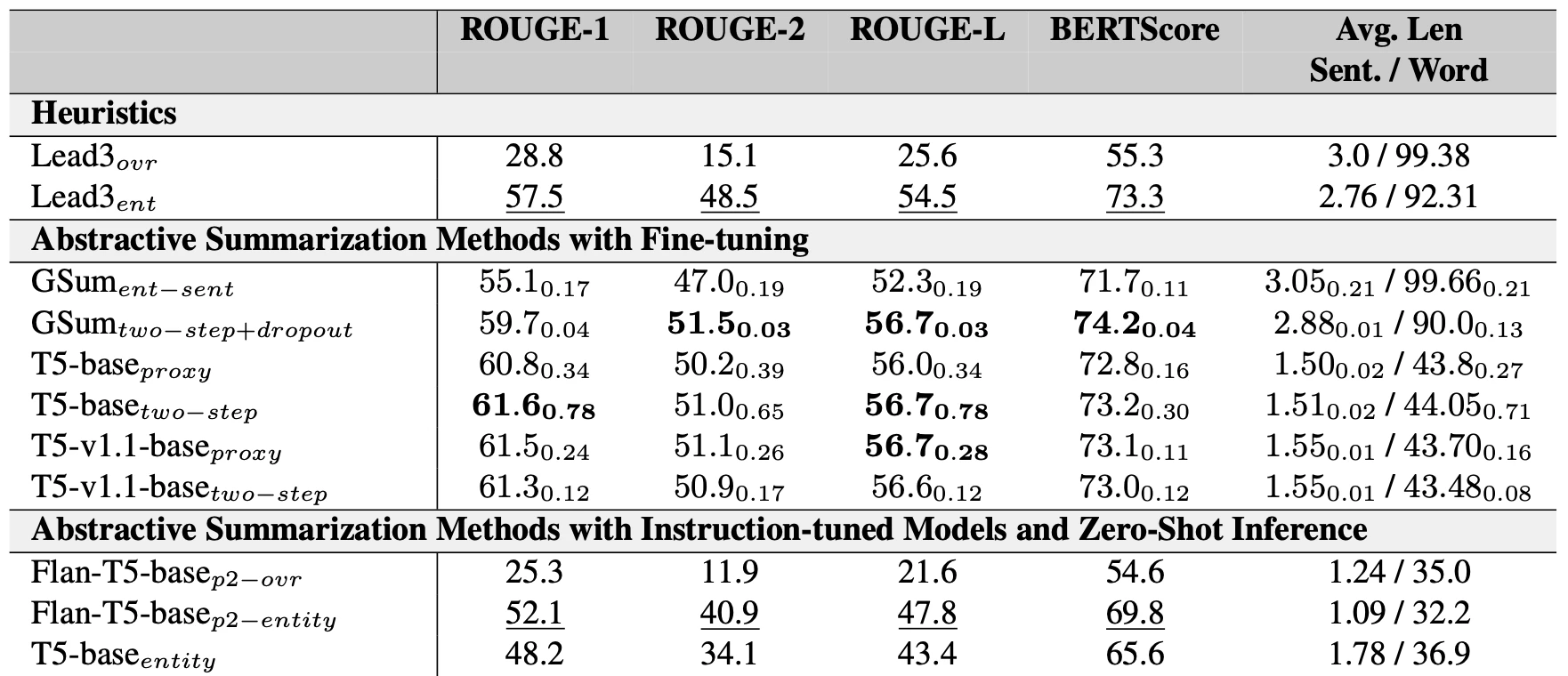
Dhruv: As you can see, it is clear that fine-tuned models (the middle section) fare much better than instruction-tuned models (the last section), but it is not clear what the differences between each of these models are. Are they producing short and relevant summaries about an entity that are incomplete? Or are they producing verbose and complete summaries about an entity that contain extra, yet irrelevant, information?
Ella: To answer these questions, we propose a new method of qualitative human evaluation that evaluates each model across five crucial facets that high quality entity-centric summaries possess: Entity-Specificity, Factuality, Completeness, Fluency and Quality. These qualitative metrics provide a more fine-grained interpretation of the current state-of-the-art systems.


Dhruv: We evaluated the best performing models in each category along these metrics, which reveal some insights. For example, GSum models give more relevant and complete summaries that are less fluent, while the T5-based models provide more fluent summaries that are less complete and less factually accurate.
How does your research advance the state-of-the-art in the field of natural language processing?
Dhruv: Our research provides a new dataset which can be used to evaluate models on the generative entity-centric summarization task, as well as provides a new framework for obtaining human evaluations which captures a more holistic view of the summaries as opposed to industry standard automated metrics.
Make it happen here.
Multilingual Large Language Models Are Not (Yet) Code-Switchers
Ruochen Zhang (Brown University), Samuel Cahyawijaya (HKUST), Jan Christian Blaise Cruz (Samsung R&D Institute Philippines), Genta Indra Winata (Bloomberg) and Alham Fikri Aji (MBZUAI)
Multilinguality and Linguistic Diversity 2 (Saturday, December 9, 2023 @ 11:00 AM SGT)


Please summarize your research. Why are your results notable?
Genta: Large Language Models (LLMs) have shown their potential in the context of zero-shot and few-shot prompting. The successes of these LLMs have also been effective in multilingual settings, where models are specifically trained to learn individual languages, which has proven to be highly beneficial for monolingual tasks. However, in multilingual communities, people do not confine themselves to speaking only a single language; instead, they use two or more languages interchangeably during a conversation – a phenomenon known as code-switching. This allows individuals to communicate cultural-specific concepts more effectively, signaling their group identity and reinforcing their social connection.
The main challenge of developing multilingual LLMs optimized for code-switching lies in data scarcity. Given the highly colloquial characteristic of code-switching, existing resources dedicated to code-switching are rare, and large-scale collection requires considerable annotation efforts.
In this paper, we benchmark the ability of LLMs to understand and generate code-switching on existing code-switching datasets to gauge the limitations of LLMs on four different tasks and a variety of language pairs. Figure 1 shows the illustration of tasks included in our benchmark study.

How does your research advance the state-of-the-art in the field of natural language processing?
Our results suggest that the scaling law is applicable to multilingual LLMs across diverse code-switching tasks and model architectures. However, smaller-scale, fine-tuned models substantially outperform the largest multilingual LLM with prompting methods. In addition, while hosted LLMs achieve scores comparable to our fine-tuned models, such performance remains uninterpretable due to their closed natures. We argue that existing multilingual LLMs exhibit limited proficiency in code-switching contexts, highlighting future research opportunities to transform them into true polyglots.
TempTabQA: Temporal Question Answering for Semi-Structured Tables
Vivek Gupta (University of Pennsylvania), Pranshu Kandoi
(IIT Guwahati), Mahek Bhavesh Vora (IIT Guwahati), Shuo Zhang (Bloomberg), Yujie He (Bloomberg), Ridho Reinanda (Bloomberg) and Vivek Srikumar (University of Utah)
Resources and Evaluation 2 (Sunday, December 10, 2023 @ 12:00 PM SGT)


Please summarize your research. Why are your results notable?
Shuo: Factual information pertaining to a particular entity often undergoes temporal changes, necessitating a thorough comprehension of the scope of knowledge and temporal intervals. This factual data is typically dispersed across semi-structured formats, such as tables, and includes both implicit and explicit representations (see Figure 2 for an example). The extensive presence of these characteristics presents significant challenges for NLP models, necessitating them to proficiently manage temporal changes and extract meaningful insights from time-sensitive data.
To address this issue effectively, we introduce a new task, referred to as “temporal question answering on entity-centric semi-structured tables,” demonstrated in Figure 2. Furthermore, we have curated a comprehensive, temporally-aligned dataset (TempTabQA), which covers a variety of domains and has undergone human verification. We conducted extensive experiments and found that temporal reasoning in TempTabQA presents a greater challenge compared to non-temporal reasoning in preceding tabular datasets.

How does your research advance the state-of-the-art in the field of natural language processing?
Our paper is a significant step forward because it’s the first to develop complex datasets for answering time-based questions that are specifically designed for tables focused on specific topics or entities. Our main goal was to introduce a new challenge – answering complex questions about time within this context.
The TempTabQA dataset requires not only high-level reasoning but also a solid understanding of how time works, as well as good math skills. Our work highlights how unique this dataset is because of its focus on time, making it different from existing models. We dig deep into this difference, providing a detailed set of statistics and analyses that show the many challenges of reasoning about time that the dataset presents. These findings help us better understand how to reason about time in tables and encourage more research in this area.
Semantic Similarity Covariance Matrix Shrinkage
Guillaume Becquin (Bloomberg) and Saher Esmeir (Bloomberg)
Findings of EMNLP 2023


Please summarize your research. Why are your results notable?
Guillaume: When building an investment portfolio, asset managers often aim to maximize the expected returns while minimizing the expected volatility (a proxy for the portfolio level of risk). A common technique to reduce the volatility is to build a diversified portfolio – find uncorrelated assets so the volatility of the portfolio is significantly lower than its individual components. Unfortunately, estimating the degree of correlation between assets in a portfolio (covariance matrix) is very challenging since the number of random variables (components of the portfolio) is typically larger than the number of historical price observations.
Covariance shrinkage is an established regularization method in quantitative finance that regularizes the estimation of the covariance matrix. Our work extends the idea of shrinkage by making use of additional information from company fundamentals to regularize the covariance matrix. Embeddings (vector representations) of portfolio components (e.g., company stocks) can be generated using modern NLP techniques via sentence encoder or knowledge graphs. These embeddings are used to compute a similarity matrix for the portfolio assets that includes fundamental information about the assets, and are an effective regularization target for use in the well-established shrinkage framework.

How does your research advance the state-of-the-art in the field of natural language processing?
Natural language processing approaches are increasingly being adopted in the fields of finance and portfolio management. Previous work has mainly focused on improving the prediction of future returns to maximize expected profit. However, the estimation of portfolio volatility is also a critical element for finding the optimum portfolio at a given level of acceptable risk (risk-return trade-off).
Our research provides a robust framework that uses the output of NLP models to produce robust estimates of the portfolio covariance matrix by extending established methods in quantitative finance. Implemented as a simple post-processing step, it is widely applicable to any semantic model (including sentence embeddings and knowledge graph embeddings).