Bloomberg’s AI Group Publishing 3 Research Papers at NAACL 2022
July 08, 2022
At the 2022 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL 2022) in Seattle, Washington, researchers from Bloomberg’s AI Engineering group will be showcasing their expertise in natural language processing (NLP) and computational linguistics by publishing three papers across the main conference and in Findings of the Association for Computational Linguistics: NAACL 2022. Through these papers, the authors and their collaborators highlight a variety of NLP applications, novel approaches and improved models used in key tasks, and other advances to the state-of-the-art in the field of computational linguistics.
In addition, Bloomberg Data Science Ph.D. Fellow Alexander Spangher, a Ph.D. candidate in the Department of Computer Science at the USC Viterbi School of Engineering, was awarded “Outstanding Paper” for his NAACL 2022 paper “NewsEdits: A Dataset of News Article Revision Histories and a Novel Document-Level Reasoning Challenge,” making it one of only eight papers receiving a distinction. Congratulations!
We asked some of our authors to summarize their research and explain why their results were notable:
Combining Humor and Sarcasm for Improving Political Parody Detection
Xiao Ao and Danae Sanchez Villegas (Computer Science Department, University of Sheffield, UK), Daniel Preoţiuc-Pietro, (Bloomberg), Nikolaos Aletras (University of Sheffield)
1F: In-Person Poster Session 1 (Monday, July 11 @ 10:45 AM–12:15 PM PDT)


Please summarize your research. Why are your results notable?
Daniel: Our paper studies the problem of automatic detection of political parody in short tweets using the dataset introduced in our previous work on this topic, which we presented at ACL 2020.
One of the hallmarks of parody expression is the deployment of other figurative devices, such as humor and sarcasm. For example, the following tweet posted by a parody account employs humoristic elements:

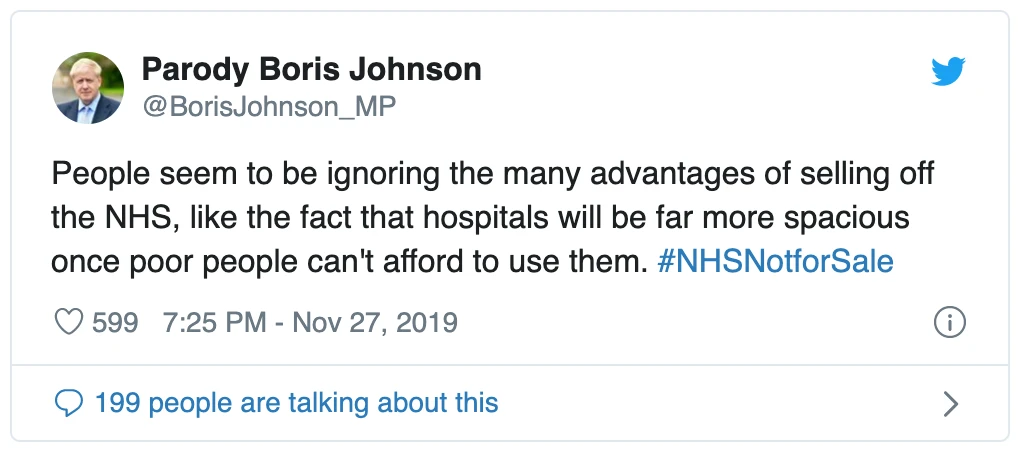
Another example is the tweet below, which uses sarcasm when it refers to MySpace as a ‘winning technology’:
We explore how to build a model that learns knowledge about humor and sarcasm and uses this to improve performance of parody detection. This is done through building humor- and sarcasm-specific encoders trained on annotated humor and sarcasm data, and then using a method to fuse this knowledge so it can be included in the parody prediction stage. Our results show that we achieve consistent improvements in all setups of the parody prediction task, and that both sarcasm and humor modeling contributes to these improvements.

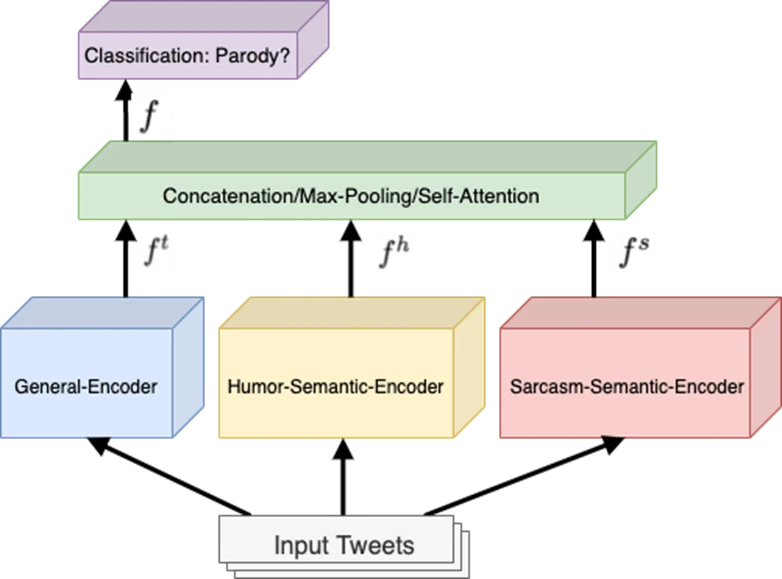
How does your research advance the state-of-the-art in the field of natural language processing?
Our paper studies the relationship between associated figurative devices, including parody, humor and sarcasm. We expect this approach will transfer to other cases where related figurative tropes or speech acts are modeled, with the goal of further improving overall prediction performance and our understanding of these devices.
Learning Rich Representation of Keyphrases from Text
Mayank Kulkarni (Bloomberg), Debanjan Mahata, Ravneet Singh Arora, Rajarshi Bhowmik (Bloomberg)
Session 9F: Findings In-person Poster Session 1 (Wednesday, July 13 @ 10:45 AM–12:15 PM PDT)


Please summarize your research. Why are your results notable?
Mayank: Pre-trained language models are foundational to most NLP tasks. They have largely been trained by masking random tokens and spans. Past research proposed masking entities to pre-train entity-representations; however, these are constrained by the entity vocabulary, and entity-type can be a limiting factor in generalizing to other applications. In contrast, keyphrases are multi-token spans that represent salient concepts or topics in a document and do not adhere to defined types or vocabularies. Figure 1 shows how keyphrases naturally occur in text and how they differ from entities and topics.

Our work aims to shine a spotlight on keyphrases and their utility in furthering NLP. In doing so, we propose the first exploration of using the pre-training objective of Text Infilling, which has found reasonable success in the encoder-decoder model (e.g., BART) and with encoder-based models (e.g., BERT and RoBERTa). We focus on trying to obscure or replace important spans of keyphrases from the document and tasking the model to predict these missing spans or to determine whether a keyphrase was replaced. We hypothesize that, in doing so, the model learns richer representations of spans and is able to acquire knowledge by learning the keyphrase that was required in place of the perturbed text.
We thus introduce two novel training setups visualized in the figures below:
- the pre-training objective of Keyphrase Boundary Infilling and Replacement (KBIR); and
- a novel generative pre-training strategy named KeyBART.
A more in-depth description is available in the paper.


How does your research advance the state-of-the-art in the field of natural language processing?
Pre-trained language models trained with masking and infiling objectives are at the foundation of many NLP tasks, such as classification, keyphrase extraction, named entity recognition, question answering, relation extraction, in addition to language generation tasks, such as keyphrase generation and abstractive summarization. We evaluate the performance of our model on all these tasks and results show that our proposed models that leverage keyphrases in pre-training significantly outperform state-of-the-art models on keyphrase extraction and keyphrase generation. Similarly, these models also perform competitively with state-of-the-art models (as of the time of publication) on other core NLP tasks.
In addition, we show that KeyBART performs well when used off-the-shelf, providing easy access for researchers and engineers to generate keyphrases from a given document. We have made these pre-trained models (KBIR and KeyBART) and the pre-training code publicly available to facilitate further research.
Make it happen here.
Falsesum: Generating Document-level NLI Examples for Recognizing Factual Inconsistency in Summarization
Prasetya Ajie Utama (Bloomberg), Joshua Bambrick, Nafise Sadat Moosavi, Iryna Gurevych (UKP Lab, Technical University of Darmstadt, Germany)
Oral Session 10B: Semantics (Wednesday, July 13 @ 2:15–3:45 PM PDT)


Please summarize your research. Why are your results notable?
Ajie: Our work addresses the problem of factual inconsistency in neural abstractive summarization models. Although recent advances in pre-training and the availability of large scale summarization approaches have led to very fluent and plausible summaries, they still often ‘hallucinate’ parts of the summaries that are unsupported by the source documents.
Prior work introduced a task for recognizing such factual inconsistencies as a downstream application of natural language inference (NLI). This earlier formulation detects inconsistencies when the summary (‘hypothesis’) text is detected to not be entailed by the document (‘premise’) text. However, state-of-the-art NLI models perform poorly in this context due to their inability to generalize to this target task. One of the reasons for this is the mismatch between the training data, which consists of sentence-level examples and the test data, which are composed of document-summary pairs. Therefore, document-level NLI examples are needed to improve this downstream application, but collecting them manually is difficult and expensive.
In this paper, we introduce Falsesum, a data generation pipeline designed to produce naturalistic document-level NLI examples automatically. Falsesum consists of a controllable text generation model that takes a source document text and its corresponding summary as an input pair, and subsequently outputs a perturbed summary that is factually inconsistent with the input. These generated inconsistent summaries are both as fluent and plausible as their factually consistent counterparts. They can then be used as high-quality training examples for a classifier model to learn to discriminate between factual and non-factual summaries.

How does your research advance the state-of-the-art in the field of natural language processing?
We used the generated training examples from Falsesum to augment the existing sentence-level NLI dataset to train an improved classifier model. To evaluate the downstream performance of the resulting NLI models after augmentation, we tested on four benchmark datasets for detecting factual inconsistency in summarization. The overall scores are shown below:

Why are your results notable?
We show that the baseline MNLI dataset (Williams et al., 2018) without augmentation performs as poorly as majority voting. We also compare against other more recent document-level NLI datasets, and observe that they do not help the downstream tasks much. Finally, we show that Falsesum-augmented data improves upon the state-of-the-art performance against all of the benchmark datasets. Our manual and ablation analysis suggest that the improved performance is mostly attributable to the diversity and plausibility of the generated false summaries. Overall, we hope that our framework and generated data can inspire future work to improve the applicability of NLI classification models, as well as the reliability of automatic summarization output.