Bloomberg’s AI Engineering Group & CTO Office Publish 5 NLP Research Papers at EMNLP 2022
December 07, 2022
During the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP 2022) in Abu Dhabi this week, researchers from Bloomberg’s AI Engineering Group and CTO Office are showcasing their expertise in natural language processing (NLP) by publishing five papers. Three papers will appear in Findings of EMNLP 2022. One of these, along with another paper, is also being presented in the virtual poster session during the Second Version of Generation, Evaluation & Metrics (GEM) Workshop 2022. A fifth paper will be presented at the 2nd Multilingual Representation Learning (MRL) Workshop.
Through these papers (links and PDFs of the papers will be added once the Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing is available online), the authors and their collaborators highlight a variety of NLP applications, novel approaches and improved models used in key tasks, and other advances to the state-of-the-art in the field of computational linguistics.
We asked some of the authors to summarize their research and explain why the results were notable:
Sequentially Controlled Text Generation
Alexander Spangher (USC Viterbi School of Engineering/Bloomberg Data Science Ph.D. Fellow), Yao Ming/Xinyu Hua (Bloomberg), Nanyun Peng (UCLA)
Findings of EMNLP 2022
GEM Workshop, Virtual Poster Session (Wednesday, December 7, 2022 @ 9:00 PM GST)
Please summarize your research. Why are your results notable?
Xinyu: We started off with a basic problem: different consumers of news require varied levels of background context, prefer specific types of article structures depending on what platform they’re reading the news and how much time they have to consume it, and often have different reasons for reading the content. So, given the main subject of a news article, could we fill in relevant contextual information? Could we experiment with different structural modes of storytelling? Could we personalize the news article to fit the different users’ needs?
The unifying principle behind all these questions is: how can we control the macro-structure of the news story we wish to write? We identified this core research question and formulated a novel AI task to address it, something we call “sequentially controlled text generation.” In this task, the algorithm is provided with a topic (i.e., in the form of a prompt) and a sequence of structural codes (i.e., “Main Event” -> “Background” -> “Previous Event”) that govern – on a sentence-level – the macro-structure we wish the generated story to exhibit.
Alex: In our work, we (1) develop baseline methods to solve this task and (2) further study how much structural awareness during story generation contributes to well-structured and fluent text. In our experiments, we use headlines as textual input to the language model and Van Dijk discourse tags (News as Discourse. Routledge. 2013.) as control codes, as illustrated in the Figure below, where “Main Event,” “Historical Event,” and “Expectation” are the control codes, conditioned on the title “Neo-Nazi murder gang member jailed for life in Germany.”

Our system combines two important approaches in text generation: generation and editing. During generation, we first perturb the output of a language model using a structurally-aware classifier and generate the next word by sampling from the perturbed distribution. Editing is performed at the end of each generated sentence: we identify the most “salient” words, which contribute the most to the discriminator’s prediction on the desired discourse class.
We use heuristics based on part-of-speech to encourage the editor to introduce explicit discourse markers, and we fine-tune a label-aware text infilling model to generate candidate edits given the masked input, which is repeated until there is an increase in likelihood of the desired control code.
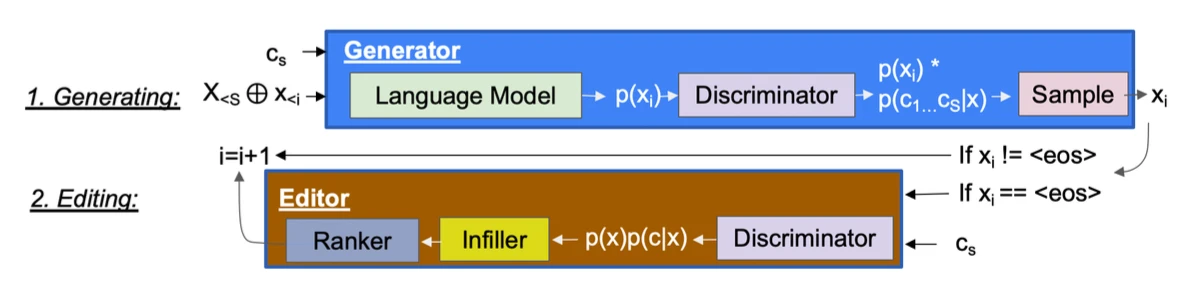
We experiment on the NewsDiscourse dataset and conduct human evaluation against four metrics: Accuracy, Grammar, Logical Flow, and Topicality. Our results show that (1) past structural information boosts class accuracy the most; (2) weak discriminators can still impose accurate control; and (3) editing has an overall positive effect on both generation accuracy and quality.
In text generation, the discourse structure impacts both human and machine comprehension. Although naive language models have made impressive advancements and generate fluent text, the text is structurally dissimilar to text written by humans. We envision this system will enable journalists to quickly prototype different structures for their work, or fill in missing structural components to aid in human-in-the-loop computational journalism.
How does your research advance the state-of-the-art in the field of natural language processing?
Xinyu: The controllability issue of neural generation models is the key hurdle for their real world adoption. Existing controllable models focus on single control code (i.e., one signal per document). Our work tackles structured control, which allows for more fine-grained, sequential control based on discourse structures. Our system could vary the degree of control, from local-only to past-aware, and even to full-sequence control. Furthermore, we employ editing as part of our pipeline to continuously improve the output quality. We showcase this system on a news dataset and conduct extensive human evaluation to confirm the improved generation quality and resemblance to human-written text over the original, uncontrolled GPT-based model.
Make it happen here.
Realistic Data Augmentation Framework for Enhancing Tabular Reasoning
Dibyakanti Kumar (IIT Guwahati), Vivek Gupta (University of Utah/Bloomberg Data Science Ph.D. Fellow), Soumya Sharma (IIT Kharagpur), Shuo Zhang (Bloomberg)
Findings of EMNLP 2022
Please summarize your research. Why are your results notable?
Shuo: The challenge of classifying a hypothesis as entailment, contradiction, or neutral depending on the provided premise is known as Natural Language Inference (NLI). For NLI tasks like semi-structured table reasoning, there are currently two main ways to create training data: via crowdsourcing or through fully automatic techniques. Notably, the former restricts scalability since it is costly and time-consuming, while the latter frequently yields simplistic instances that could lack complex reasoning.
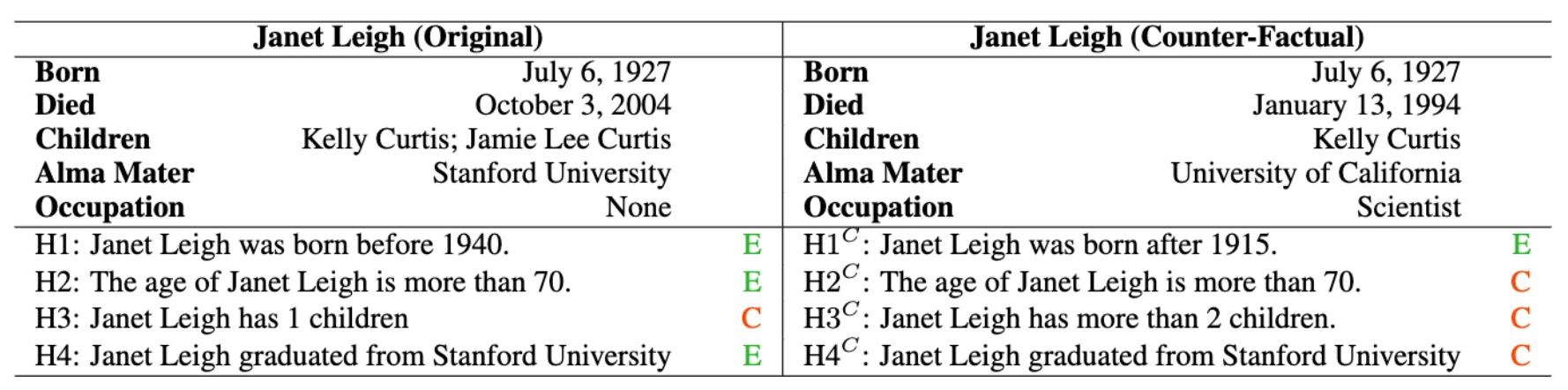
Our work develops a realistic semi-automated framework for data augmentation for tabular inference. Instead of manually generating a hypothesis for each table, our methodology generates hypothesis templates that are transferable to similar tables (see Table 1 for examples). In addition, our framework entails the creation of rational counterfactual tables based on human-written logical constraints and premise paraphrasing. We employ InfoTabs, an entity-centric tabular inference dataset, for our study. We found that our methodology could provide examples of tabular inference that resembled those made by humans. As such, this approach could help with training data augmentation, especially in the case of limited supervision.
How does your research advance the state-of-the-art in the field of natural language processing?
Existing approaches for curating training data are limited in scale or suffer from biases, especially for reasoning on semi-structured tabular data. Our proposed semi-automatic framework can exploit the tabular structure for hypothesis generation, which can then be further transferred to similar tables. Data augmentation would then be another option for curating training data for table reasoning tasks.
Weakly Supervised Headline Dependency Parsing
Adrian Benton (Bloomberg), Tianze Shi (Cornell University/Bloomberg Data Science Ph.D. Fellow), Ozan İrsoy/Igor Malioutov (Bloomberg)
Findings of EMNLP 2022
Please summarize your research. Why are your results notable?
Igor: The unique syntactic properties of English news headlines have been noted in linguistics literature since the 1930s. However, headlines have received surprisingly little attention from the Natural Language Processing (NLP) community in the context of automatic syntactic analysis or parsing. This presents an important limitation regarding headline processing, since correctly analyzing the syntactic structure of text is often critical for accurate semantic understanding, as well as the effectiveness of downstream systems for summarization, information extraction, and question answering.
We bridge this gap by providing the first annotated English news headline corpus of Universal Syntactic dependency parse trees, which enables us to evaluate state-of-the-art dependency parsers on news headlines. To improve the accuracy of English news headline parsing, we develop a method to automatically bootstrap noisy training data from pairs of unlabeled headlines and the lede sentences from the body text.
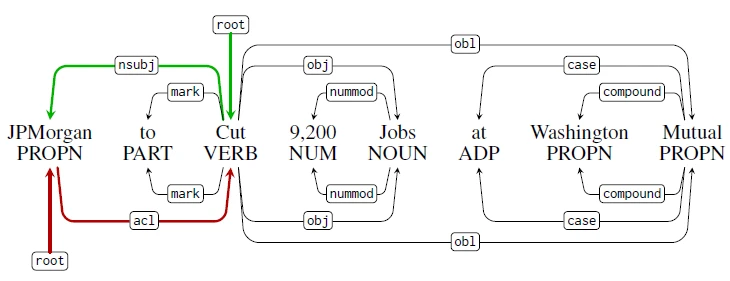
Our approach is based on a key observation: headlines convey similar semantic content as the news story body – and they typically share many local substructures. The first sentence in an article, known as a lede sentence, often serves a similar function as the headline. It is meant to grab the reader’s attention and states essential facts about a news event; lede sentences are sometimes direct expansions of the headlines.
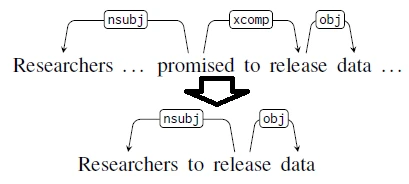
Our bootstrapping algorithm projects and carries over the syntactic dependency analysis from the lede sentence to the headline by pruning the lede sentence’s dependency trees. Because existing models are accurate in parsing long-form news body texts, the resulting silver headline parsed from our bootstrapping algorithm is typically more accurate than applying existing models to headlines directly.
How does your research advance the state-of-the-art in the field of natural language processing?
Models trained on our bootstrapped silver headline parses demonstrate significant improvements in performance over models trained solely on gold-annotated long-form texts — after training with silver parses, we can accurately identify the main predicate/verb of a sentence up to 98% of the time (up from 75%), and can correctly identify passive construction with up to 91% accuracy (from 11%). Furthermore, we show that these gains translate to downstream improvements in the quality of output extracted by a state-of-the-art open domain information extraction system from headlines.
We hope our data, models, and methodology will encourage further research to improve dependency parsers for overlooked registers of English. In addition, we hope the development of accurate headline dependency parsers will improve the performance of existing headline understanding and processing tasks and enable more subtle linguistic analysis, such as the identification of “crash blossoms” (i.e., ambiguous news headlines).
What Makes Data-to-Text Generation Hard for Pretrained Language Models?
Moniba Keymanesh, Adrian Benton, Mark Dredze (Bloomberg)
GEM Workshop, Virtual Poster Session (Wednesday, December 7, 2022 @ 9:00 PM GST)

Please summarize your research. Why are your results notable?
Moniba: In its role as a leading provider of financial information, Bloomberg maintains a massive database of structured information. Access to this information usually comes in the form of API calls. While users can access this information programmatically, delivering it to users often requires formatting the information as natural language. For example, a Bloomberg journalist may fact-check information about a company or look up an executive’s bio using the Bloomberg Knowledge Graph (BBKG) before incorporating it into a story. This process can even be semi-automated or fully automated, but both processes initially require complex engineering efforts. Moreover, question answering from the Terminal commandline seamlessly provides direct access to structured information, but supporting different question and information types requires significant engineering effort.
The central challenge across these tasks is how to take structured information and express it as fluent and accurate natural language. The goal of this project is to develop a system that takes as input one or more sets of structured facts or relations (triples) and produces natural language text that expresses this information. This task is closely related to data-to-text generation in natural language processing literature. Automated data-to-text generation systems take as input a set of relations, where each relation is a (subject, predicate, object) triple(see an example below). Applications of this technology include story or dialogue generation, open-domain question-answering, and text summarization. Domains may span journalism, weather, finance, sports, and even the summarization of patient medical histories.

Previous work shows that pre-trained language models (PLMs) perform remarkably well on this task after supervised learning on a significant amount of data. However, dataset creation for this task can be challenging and not feasible in many domains. On the other hand, while auto-regressive PLMs such as GPT can generalize from a few task examples, their data efficacy at data-to-text is largely unexplored. Furthermore, we have an incomplete understanding of the limits of PLMs on this task. These issues make the path forward for data-to-text generation research unclear.
In this work, we conduct an evaluation of PLMs for data-to-text generation generation, focusing on two classes of challenging examples: examples with novel (unseen) relations (predicates) and examples where the source and target sequences are lexically very different (i.e., not amenable to purely extractive data-to-text generation systems). We consider how GPT-2, adapted with few-shot learning, prompt tuning, and the addition of predicate descriptions, performs on these example classes as compared to a state-of-the-art fine-tuned T5. While GPT-2 performs poorly on DART in the zero-shot setting, we show that its performance can be drastically improved by employing the above techniques.
How does your research advance the state-of-the-art in the field of natural language processing?
In this work, we contribute to the data-to-text generation research by benchmarking and analyzing the limitations of two popular PLMs on the multi-domain DART dataset. We also provide recommendations for future model and dataset research in data-to-text generation. Essentially, we make the following contributions:
- We evaluate GPT2-XL and fine-tuned T5 for data-to-text generation. While the zero-shot GPT model performs poorly, we evaluate several strategies to improve performance, including few-shot learning and prompt tuning. Both provide significant improvements on the DART dataset.

- We compare model performance on two classes of difficult examples: examples with unseen predicates and abstractive examples (i.e., examples where source and target sequences are lexically dissimilar). We investigate whether including predicate descriptions in the prompt can improve the ability of PLMs on these classes.
- We conduct a human evaluation of PLMs to quantify the prevalence of errors such as hallucination and missing information in generations as a function of the model adaptation technique. We find that a re-ranking strategy for few-shot GPT2-XL, despite having little effect on automatic metrics like BLEU, reduces the incidence of missing information, without requiring additional training data.
Entity Retrieval from Multilingual Knowledge Graphs
Saher Esmeir (Bloomberg), Arthur Câmara (Delft University of Technology), Edgar Meij (Bloomberg)
MRL Workshop, Poster Session (Thursday, December 8, 2022 @ 11 AM GST)
Please summarize your research. Why are your results notable?
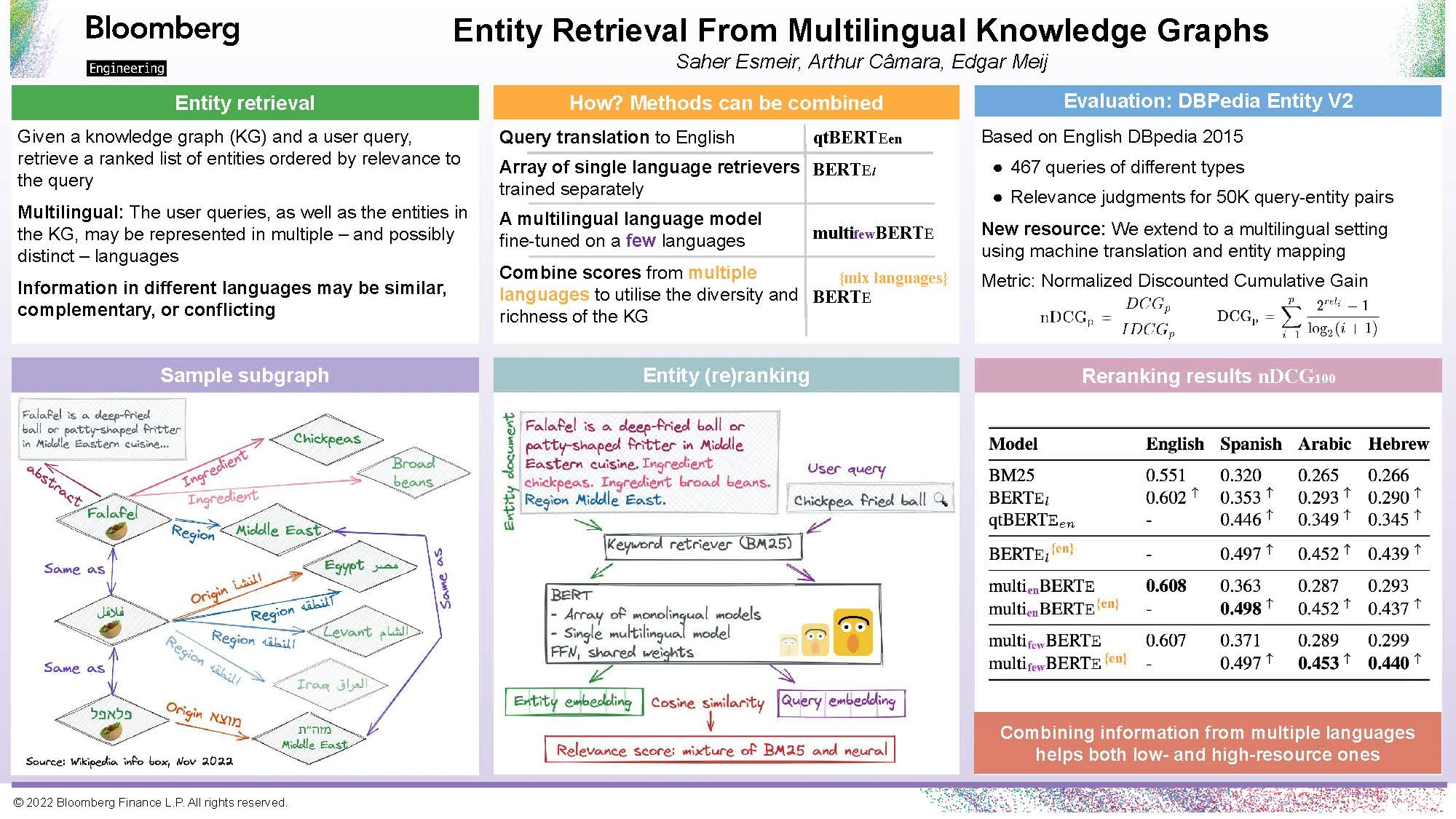
Saher: Given a knowledge graph (KG) and a user query, the task of entity retrieval aims to retrieve a ranked list of entities ordered by relevance to the query. In this work, we define and address the multilingual entity retrieval task in which the user queries, as well as the entities in the KG, may be represented in multiple, possibly distinct, languages.
Due to different data sources and points of view, information in different languages may be similar, complementary, or conflicting. To benefit from this diversity, we propose to leverage multilingual language models. In the training stage, we fine-tune the language models on data from multiple languages. In the retrieval stage, we use machine translation to obtain results for different versions of the same query and then blend the scores to produce our final ranking.
How does your research advance the state-of-the-art in the field of natural language processing?
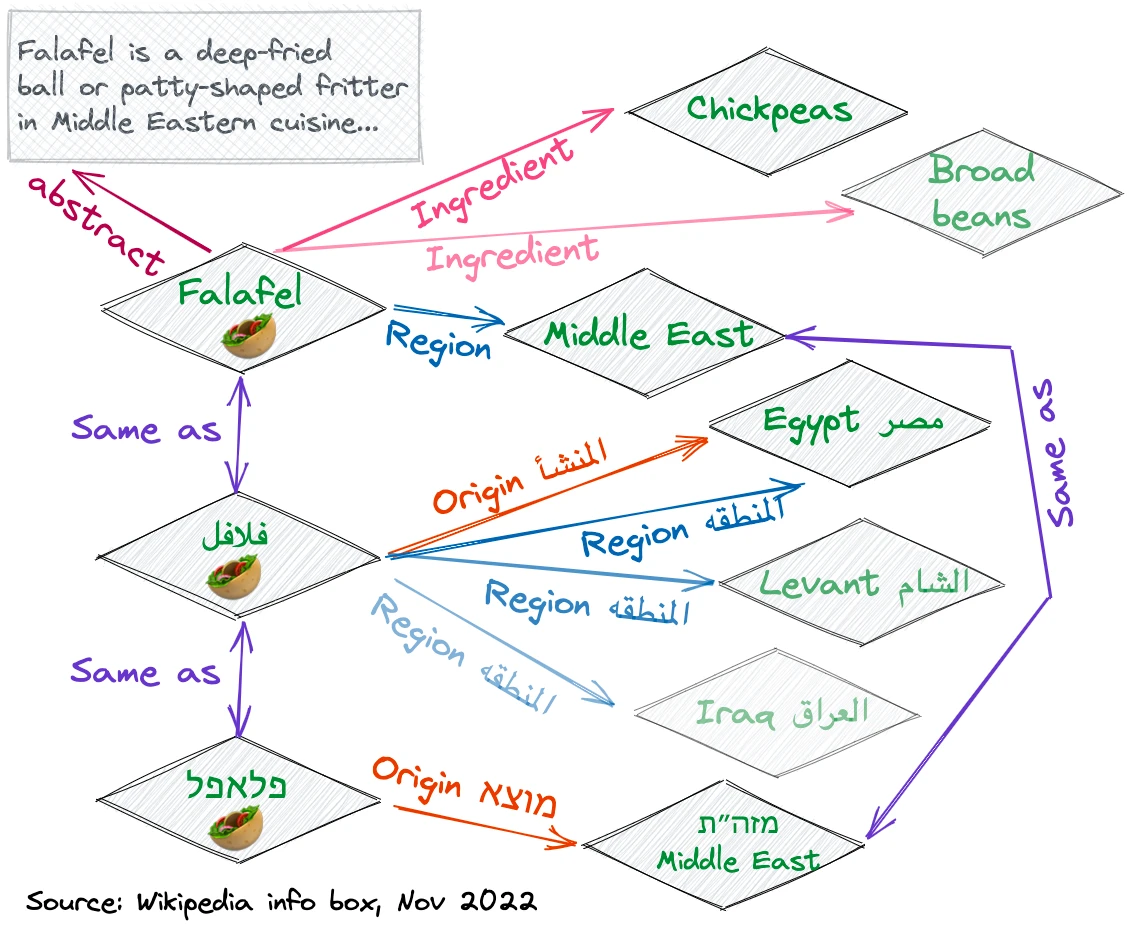
The performance of our system on the standard test collection, DBpedia Entity v2, where both the knowledge graph and the query are in English, is comparable to that of state-of-the-art methods. However, thanks to its simplicity and flexibility, our method can be extended to virtually any language that is represented in the searched graph, producing strong baseline results for many languages.
Furthermore, we show that, even for highly-resourced languages such as English, taking information from other languages can significantly improve the retrieval performance when relevant coverage in multiple languages is available.
Finally, we provide a resource for multilingual entity retrieval by extending the English-only DBpedia Entity v2. The extended version provides judged relevance scores for query-entity pairs in any language, provided machine translation is supported and the entity exists in the DBpedia edition of that language.