Bloomberg’s AI Group & CTO Office Publish 8 Research Papers at ACL 2022
May 23, 2022
At the 60th Annual Meeting of the Association for Computational Linguistics (ACL 2022) this week in Dublin, Ireland, researchers from Bloomberg’s AI Group and Office of the CTO are showcasing their expertise in natural language processing (NLP) and computational linguistics by publishing 8 papers across the main conference, the 5th Fact Extraction and VERification (FEVER) Workshop, and ‘Findings of the Association for Computational Linguistics: ACL 2022.’ Through these papers, the authors and their collaborators highlight a variety of NLP applications in finance, novel approaches and improved models used in key tasks, and other advances to the state-of-the-art in the field of computational linguistics.
We asked some of the authors to summarize their research and explain why the results were notable:
EntSUM: A Data Set for Entity-Centric Summarization
Mounica Maddela (Georgia Institute of Technology), Mayank Kulkarni and Daniel Preoţiuc-Pietro (Bloomberg)
Oral Session 4-7: Summarization 1 (Tuesday, May 24, 2022 @ 11:00-11:15 IST)
Poster Session 5-3: Summarization [#39] (Tuesday, May 24, 2022 @ 15:15-16:15 IST)
Virtual Poster Session 1 (Tuesday, May 24, 2022 @ 07:30-08:30 IST)


Please summarize your research. Why are your results notable?
Mayank: Summarization is the task where an automatic summary for a news article is generated or extracted from the original content. Our paper focuses on entity-centric summarization, where summarization is performed with respect to a target entity provided by the user of the system. The figure below shows an example of this, where the generic summary for the news article is very different from and has low overlap with entity-centric summaries generated with respect to the entities mentioned in the document. We see the entity-centric summaries thus provide new information that wasn’t available in generic summary, allowing us to perform a more faceted analysis of the document. This is a relatively new task where no standard evaluation exists, so the paper introduces a new dataset named EntSUM, which consists of 2,788 human-generated entity-centric summaries across 645 documents from The New York Times’ corpus, for which generic summaries also exist. As the task of generating the summary is complex, the dataset was annotated in four distinct steps, starting with identifying salient entities, identifying all sentences about the entity, the salient sentences for the entity and, finally, writing a summary using the salient sentences.


We benchmark both abstractive methods, which generate the summary entirely, and extractive methods, which select the sentences from the original news article, on this new dataset and introduce a new training procedure by which we can use generic summaries to train an entity-centric summarization method. Our results show that past methods that claim to perform controllable summarization are not well suited to this task, that our proposed methods perform reasonably well, and that the proposed task is very challenging.
How does your research advance the state-of-the-art in the field of natural language processing?
High-quality reference datasets are needed to foster development and facilitate benchmarking. This paper introduces the first annotated dataset for entity-centric summarization and provides an initial comparison of multiple state-of-the-art summarization methods.
Automatic summarization aims to extract key information from a large document and to present a coherent summary for the user to digest the core information in the document faster and more easily. Generating a single summary of a document is not suitable for all readers of the document, as each user may have different interests. We believe the wider ability to control or personalize summaries to aspects like target entities, terms of interest, style, or level of detail will be paramount in enabling the widespread usability of summarization technology. We also make our implementation openly available.
Make it happen here.
One Country, 700+ Languages: NLP Challenges for Underrepresented Languages and Dialects in Indonesia
Alham Fikri Aji, Genta Indra Winata (Bloomberg), Fajri Koto, Samuel Cahyawijaya, Ade Romadhony, Rahmad Mahendra, Kemal Kurniawan, David Moeljadi, Radityo Eko Prasojo, Timothy Baldwin, Jey Han Lau, Sebastian Ruder
Oral Session 4-6: Special Theme on Language Diversity: From Low Resource to Endangered Languages (Tuesday, May 24, 2022 @ 11:00-11:15 IST)
Poster Session 6-3: Special Theme on Language Diversity: From Low Resource to Endangered Languages [#73] (Wednesday, May 25, 2022 @ 10:45-12:15 IST)
Virtual Poster Session 2: Special Theme on Language Diversity: From Low Resource to Endangered Languages (Tuesday, May 24, 2022 @ 19:00-20:00 IST)

Please summarize your research. Why are your results notable?
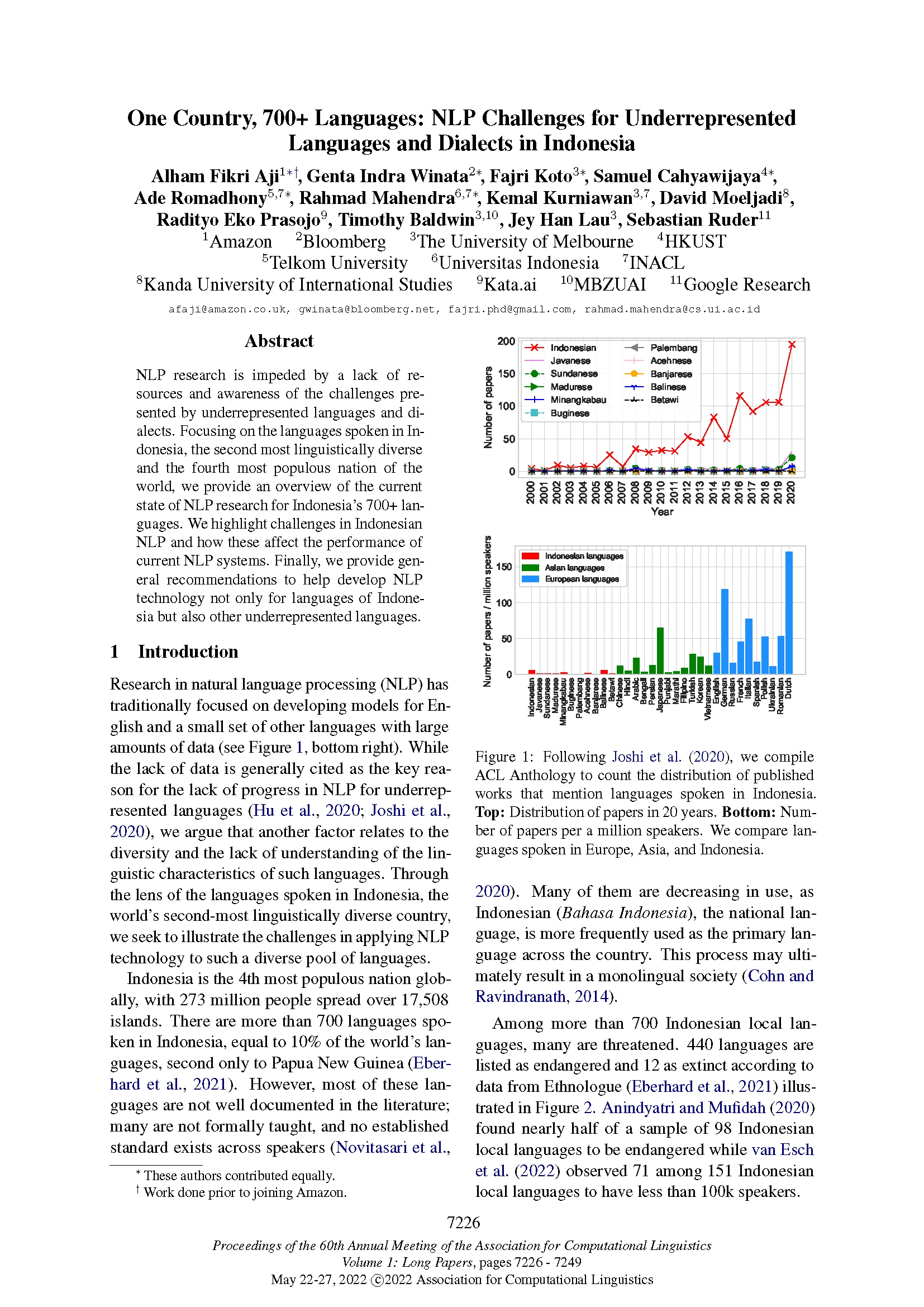
Genta: The paper provides an overview of the current state of NLP research for Indonesia’s 700+ languages, where many of the languages are underrepresented in the NLP community. We focus on the languages spoken in Indonesia, the second-most linguistically diverse nation in the world (second only to Papua New Guinea according to Ethnologue). We highlight challenges in Indonesian NLP and how these affect the performance of current NLP systems. Finally, we provide general recommendations to help develop NLP technology not only for languages of Indonesia, but also other underrepresented languages, and ways to promote these languages more broadly to the world.
How does your research advance the state-of-the-art in the field of natural language processing?
With 273 million people spread over 17,508 islands, Indonesia is the fourth most populous nation globally. Through the lens of the 700+ languages spoken in Indonesia (about 10% of the world’s languages), we seek to illustrate the challenges in applying NLP technology to such a diverse pool of languages.


Despite their large speaker populations, the local languages depicted in the figures above are poorly represented in the NLP literature. Compared to Indonesian, the number of research papers mentioning these languages has barely increased over the past 20 years (Figure 1). Furthermore, compared to their European counterparts, Indonesian languages remain drastically understudied (Figure 2).
Another challenge we faced in our research into Indonesian NLP is that most of these Indonesian languages are not well documented in the literature; many are not formally taught, and no established standard exists across speakers. Indonesian languages are very diverse in terms of dialects and lexical variations, depending especially on geographical location. Moreover, Indonesian and its local languages have multiple styles, even within the same dialect.
In summary, this paper aims to describe the characteristics of Indonesian languages that led to challenges in developing NLP systems for them. Based on the challenges highlighted, we formulate proposals for improving the state of Indonesian NLP research, such as providing metadata documentation, potential research direction, and promoting engagement with local NLP and linguistic communities. We hope these recommendations can offer positive guidance to encourage more research work on Indonesian languages.
IMPLI: Investigating NLI Models’ Performance on Figurative Language
Kevin Stowe & Iryna Gurevych (Technical University of Darmstadt), and Ajie Utama (Bloomberg)
Virtual Poster Session 2: Semantics (Tuesday, May 24, 2022 @ 19:00-20:00 IST)
Virtual Poster Session 4: Semantics (Wednesday, May 25, 2022 @ 19:00-20:00 IST)


Please summarize your research.
Ajie: This work focuses on the task of Natural Language Inference (NLI), in which the aim is to classify whether a hypothesis text is entailed, contradicted, or neutral with respect to the given premise text. NLI requires models to capture the semantic relationship between what is input, and thus needs to properly represent a wide range of phenomena, including figurative language such as idioms and metaphors. For instance, a premise sentence “The old man kicked the bucket” entails the hypothesis sentence “The old man died.” However, modifying the premise so it reads “The old man kicked the bucket across the lawn” will void the entailment relationship. Such examples require an understanding of the association between figurative phrases and their literal definition, while also identifying whether the phrase appears in a literal or figurative context.
Until recently, researchers have conducted fine-grained studies on the performance of NLI models through various phenomena-specific evaluations. However, models’ ability to understand figurative language remains understudied due to insufficient large-scale resources containing NLI examples that pair literal text with their figurative counterparts. The creative nature of figurative language makes it difficult and time-consuming to collect a diverse and high-quality NLI dataset for figurative language evaluation.
In this work, we introduce the Idiomatic and Metaphoric Paired Language Inference (IMPLI) dataset, an English dataset consisting of paired sentences spanning idioms and metaphors. We propose a novel data collection approach that includes semi-automated generation of NLI pairs (silver data), as well as manual handwritten NLI pairs (gold data). We summarize the annotation strategies in the following table:

Each pair consists of a sentence containing a figurative expression (idioms or metaphors) and a literal counterpart, designed to be either entailed or non-entailed by the figurative expression. The following shows some examples from IMPLI:

Why are your results notable?
Our proposed semi-automated approach results in the creation of an NLI dataset for figurative language evaluation that is significantly larger than its predecessors, consisting of 24,029 silver pairs and 1,831 gold pairs. This dataset allows us to perform two sets of experiments. First, we conducted a fine-grained performance analysis of state-of-the-art NLI models on various subsets of the dataset which are defined by two categories: (i) the type of figurative language (e.g., idioms); and (ii) the strategy used to construct the hypothesis sentence (e.g., replacing the idiom phrase in the premise sentence with an adversarial literal definition to obtain non-entailment relationship). The analysis demonstrates that NLI models perform well on entailment examples, but do poorly on the non-entailments subsets.
Second, we use IMPLI to augment the existing NLI dataset to study whether explicit examples can help models better understand figurative language. We found that incorporating idiomatic expressions into the training data is less helpful than expected. This suggests that the existing pre-trained language models are still limited in learning to represent figurative language expression in context.
How does your research advance the state-of-the-art in the field of natural language processing?
Our work has shed light on the limits of high-performing NLI models in understanding figurative language. It sheds light on how existing models work well on associating figurative expressions with their literal counterpart, but often fail to identify whether the phrases appear in their figurative or literal context. This insight can inspire future work to improve how models represent creative language. IMPLI is intended to serve as a benchmark to meaningfully measure progress in this direction. Plus, the data collection approach that we propose can be adapted to various NLP tasks in order to collect datasets that include challenging examples that contain figurative expressions.
Automatic Identification and Classification of Bragging in Social Media
Mali Jin & Nikolaos Aletras (University of Sheffield), Seza A Dogruoz (Ghent University), and Daniel Preoţiuc-Pietro (Bloomberg)
Oral Session 6-1: Computational Social Science (Wednesday, May 25, 2022 @ 11:15-11:30 IST)
Poster Session 3-1: Computational Social Science (Monday, May 23, 2022 @ 17:00-18:00 IST)
Virtual Poster Session 1: Computational Social Science (Tuesday, May 24, 2022 @ 07:30-08:30 IST)


Please summarize your research. Why are your results notable?
Daniel: In “Automatic Identification and Classification of Bragging in Social Media,” we study the speech act of bragging using NLP methods. We introduce the task of identifying if a text contains bragging and then categorizing it against six types of bragging, such as bragging about an achievement (e.g., having a paper accepted to a conference) or a possession (e.g., ownership of an expensive object). We create and release a new annotated dataset of over 6,000 tweets and use this to train models that can automatically predict bragging and its type using only the text content. Models that use various Transformer-based pretrained language models and their combination with linguistic features achieve up to 72 F1 for binary classification. Furthermore, we uncover linguistic markers associated with bragging, such as a focus on the past and use of personal pronouns and temporal references when bragging.
| Bragging Type | Definition | Example tweet |
| Achievement | Concrete outcome obtained as a result of the tweet author’s actions. These may include accomplished goals, awards and/or positive change in a situation or status (individually or as part of a group) | Finally got the offer! |
| Action | Past, current or upcoming action of the user that does not have a concrete outcome | Guess what! I met Matt Damon today! |
| Feeling | Feeling that is expressed by the user for a particular situation | thank you, I’m feeling great as always |
| Trait | A personal trait, skill or ability of the user | To be honest, I have a better memory than my siblings |
| Possession | A tangible object belonging to the user | Look at our Christmas tree! I kinda just wanna keep it up all year! |
| Affiliation | Being part of a group (e.g., family, fanclub, university, team, company etc.) and/or a certain location including living in a city, neighborhood or country | My daughter got first place in the final exam, so proud of her! |
| Not Bragging | The tweet is not about bragging or (a) there is not enough information to determine that the tweet is about bragging; (b) the bragging statements belong to someone other than the author of the tweet; (c) the relationship between the author and people or things mentioned in the tweet are unknown | Glad to hear that! Well done Jim! |
How does your research advance the state-of-the-art in the field of natural language processing?
This is the first computational study of bragging. Bragging is the act of disclosing positively valued attributes about the speaker or their in-group in order to build a positive social image. Hence, bragging is employed as a self-presentation strategy, which can further lead to personal rewards such as an increase in perceived competence or likeability. Bragging is especially prevalent in social media, encouraged by platform rewards (e.g., likes) and a higher degree of anonymity between users.
We thus formulate a new predictive task for NLP research and introduce the first large scale dataset to facilitate research on this topic. The ability to automatically infer bragging statements will enable large-scale analysis of bragging online across time or cultures. It will also enable researchers to study which bragging strategies are most effective or when bragging is employed in conversations and model it accordingly.
Extensions to this work includes studies on how bragging behavior varies across time, cultures, or user traits (e.g., extraversion and narcissism are likely associated with bragging online). Bragging is known to be a risky act as it can lead to dislike, so future studies can look into what can make bragging be perceived positively and what strategies are employed when bragging during conversations.
Updated Headline Generation: Creating Updated Summaries for Evolving News Stories
Sheena Panthaplackel (The University of Texas at Austin), Adrian Benton (Bloomberg), Mark Dredze (Bloomberg/Johns Hopkins University)
Oral Session 6-3: Generation 2 (Wednesday, May 25, 2022 @ 11:15-11:30 IST)
Poster Session 5-2: Generation (Tuesday, May 24, 2022 @ 15:15-16:15 IST)
Virtual Poster Session 3: Generation (Wednesday, May 25, 2022 @ 07:30-08:30 IST)


Please summarize your research. Why are your results notable?
Mark: The goal of headline generation is to have a system read an article and create a headline for that article. Creating a headline requires several skills, such as being able to identify the key elements of a news article, and knowing how to concisely deliver that information in headline form. People are pretty good at this task. They can quickly identify key elements of a news story and articulate them concisely. If we can build computer systems that can do the same, they may be able to perform other important tasks, such as identifying the key elements of a long news article for a reader.
In our paper, we considered a new version of this task: “Updated Headline Generation.” Instead of asking a system to create a headline for a news article, we asked the system to rewrite an existing headline for an updated article. For example, we may have an article about new legislation being proposed by Congress for a vote. An updated version of that article may be published that reflects a veto threat by the President of the United States. We want the system to learn to rewrite the headline “Congress considers new legislation” to “New legislation in jeopardy after presidential veto threat.”
This new version of the task poses considerable challenges for a headline generation system. What are the most important new aspects of the story? Should the headline be tweaked or completely rewritten? Do the changes to the story justify a change to the headline?
We found that our system learned interesting patterns in how headlines are updated. For example, the system learned how events progressed over time, as well what small details in a story were worth including in an updated headline. We found that our models were capable of learning to identify important details even if the change in the story’s language was subtle. For example, the headline “Man charged with theft of ice cream van in Nottingham” was changed to “Man admits theft of ice cream van in Nottingham” when the article’s text changed from “has been charged” to “has admitted stealing.”

How does your research advance the state-of-the-art in the field of natural language processing?
The goal of machine summarization is to produce a concise written summary of a longer article. Summaries are ubiquitous. News articles are summarized by headlines, research articles are summarized by abstracts, and many long blog posts contain a TL;DR at the top. Teaching computers how to summarize long pieces of text can help people find important information more quickly.
We normally think of summarization based solely on the given text. Take an article, email, blog post, or novel and tell me the most important information. However, we often ignore a critical piece of information: what the reader already knows. How you summarize the second book in a trilogy depends on whether or not the user already read the first book. Our “Updated Headline Generation” task casts summarization in this paradigm. If you read an article, and I update that article, how can I summarize the new information relative to what you already know? This work is a first step toward considering this important problem.
We’ve released our dataset to support further research on this topic.
Right for the Right Reason: Evidence Extraction for Trustworthy Tabular Reasoning
Vivek Gupta & Vivek Srikumar (University of Utah), Shuo Zhang, Alakananda Vempala, Yujie He, and Temma Choji (Bloomberg)
Oral Session 6-3: Semantics 3 (Wednesday, May 25, 2022 @ 11:15-11:30 IST)
Poster Session 4-4: Semantics (Tuesday, May 24, 2022 @ 11:00-12:30 IST)
Virtual Poster Session 1: Generation (Tuesday, May 24, 2022 @ 07:30-08:30 IST)


Please summarize your research. Why are your results notable?
Vivek: Tabular Inference is a reasoning task that, like conventional Natural Language Inference (NLI), asks whether a natural language hypothesis can be inferred from a tabular premise. In this work, we introduce the “Trustworthy Tabular Reasoning” task. The goal of this task is to extract “evidence” in addition to predicting whether a hypothesis entails, contradicts, or is neutral to a premise table.
Consider the following premise table:


Hypothesis H1 is entailed by it, H2 is neither entailed nor contradictory (neutral), and H3 is a contradiction. The relevant column shows the hypotheses that use the corresponding row and are the “evidence” for the entail/contradiction/neutral relationship between the table and the hypotheses. The colored text (and superscripts) in the table and hypothesis highlight token-level relevance.
We enrich InfoTabS, a tabular NLI dataset with 16,248 table-hypothesis pairs labeled with the evidence rows. Our annotators achieved substantial agreement (average Kappa score of 0.79) and a human performance of 89.49% (F1-score w.r.t. majority vote). We propose a two-stage sequential prediction approach, which includes evidence extraction and inference stages. In the evidence extraction stage, the model extracts the necessary information needed for the second stage. In the inference stage, the NLI model uses only the extracted evidence as the premise for the label prediction task. Our evidence extraction strategy outperforms earlier baselines. On a downstream tabular inference task, using only the automatically extracted evidence as the premise, our approach outperforms prior benchmarks.
How does your research advance the state-of-the-art in the field of natural language processing?
Existing NLI systems optimize solely for entail/contradiction/neutral label prediction. It is insufficient for a model to be merely right; they must also be right for the right reasons. In particular, identifying the relevant elements of inputs as the ‘right reasons’ is essential for trustworthy reasoning. We address this issue by introducing the task of “Trustworthy Tabular Inference,” where the goal is to extract relevant rows as evidence and predict inference labels. We investigate a variety of unsupervised evidence extraction techniques. Our unsupervised approach for evidence extraction outperforms previous methods. We enrich the InfoTabS dataset with evidence rows, and develop a supervised extractor that has near-human performance. Finally, we demonstrate that our two-stage technique with best extraction outperforms all prior benchmarks on a downstream NLI task.
XInfoTabS: Evaluating Multilingual Tabular Natural Language Inference (FEVER Workshop at ACL 2022)
Bhavnick Singh Minhas & Anant Shankhdhar (Indian Institute of Technology, Guwahati), Vivek Gupta (University of Utah), and Shuo Zhang (Bloomberg)
In-person Poster Session (Thursday, May 26, 2022 @ 14:00-14:30 IST)


Please summarize your research. Why are your results notable?
Shuo: Our work extends the task of tabular inference, that is predicting if a claim is true (entail), false (contradict), or can’t be determined (neutral) for multilingual settings. While significant progress in tabular reasoning has been made, these advancements are limited to English due to the absence of multilingual benchmark datasets for semi-structured data. To this end, we propose a multilingual extension of the InfoTabS dataset, a.k.a. XInfoTabS, which is a tabular inference benchmark on Wikipedia tables. This new dataset we created consists of ten languages (i.e., English, German, French, Spanish, Afrikaans, Russian, Chinese, Korean, Hindi, and Arabic), which belong to seven distinct language families and six unique writing scripts (see Table).

Note, these languages are also the majority spoken in all seven continents and cover 2.76 billion native speakers, in comparison to 360 million English language speakers. We also establish several model benchmarks with various training/evaluation strategies to study the challenges of XInfoTabS. As a result, this dataset will contribute to increased linguistic inclusion in tabular reasoning research and applications.
How does your research advance the state-of-the-art in the field of natural language processing?
Tabular data is far more challenging to translate with existing state-of-the-art translation systems than semantically complete and grammatical sentences. The intuitive method of constructing XInfoTabS (i.e., manual translation) has limited extensibility. Manual annotation necessitates the use of linguistic experts from multiple languages, which adds needless cost and delays to model deployment. Alternatively, we used various state-of-the-art machine translation models. Specifically, we propose an efficient, high-quality translation pipeline that utilizes Name Entity Recognition (NER) and table context in the form of category information to convert table cells into structured sentences prior to translation.
We assess the translations via several automatic and human verification methods to ensure quality. Our translations were found to be accurate for the majority of languages, with German and Arabic having the most and least exact translations, respectively.
This resource certainly can be used as the benchmark for multilingual tabular NLI. Our investigations reveal that these multilingual models, when assessed for additional languages, perform comparably to English for other high-resource languages with similar training data sizes. Second, this translation-based technique outperforms all other approaches on the adversarial evaluation sets for multilingual tabular NLI in terms of performance. Third, the method of intermediate-task finetuning, also known as pre-fine tuning, significantly improves performance by fine-tuning on additional languages prior to the target language. Finally, these models perform admirably on cross-lingual tabular NLI (tables and hypotheses given in different languages), although additional effort is required to further improve them.
Efficient Argument Structure Extraction with Transfer Learning and Active Learning (Findings of the Association for Computational Linguistics: ACL 2022)
Xinyu Hua (Bloomberg), Lu Wang (University of Michigan)
Virtual Poster Session 2: Sentiment Analysis, Stylistic Analysis and Argument Mining (Tuesday, May 24, 2022 @ 19:00-20:00 IST)
Virtual Poster Session 4: Sentiment Analysis, Stylistic Analysis and Argument Mining (Wednesday, May 25, 2022 @ 19:00-20:00 IST)


Please summarize your research. Why are your results notable?
Xinyu: Our work studies “Argumentative Relation Prediction.” Given any argument in a document, we aim to predict the existence and polarity (support or attack) of the relation from any other proposition within the same document. For instance, the following diagram illustrates the support relations among propositions in a peer review document. Notice that relations can span over long contexts, which is a key difficulty in this task.


Most existing methods rely on feature engineering, which is often difficult to adapt to new domains. More recently, pre-trained Transformer models have dramatically improved various NLP benchmarks. These models have shown great generalizability to new domains and tasks by first pre-training over large unlabeled corpora. They have started being used in argument relation prediction as well, where a pair of propositions are packed as a sequential input. The model learns to predict the relation between them. Our work presents a new context-aware model that further extends this approach. For a given proposition, the model encodes a broad context of neighboring propositions within a window size. It then predicts whether each of them supports, attacks, or has no relation to the original proposition.
For experiments, we release AMPERE++, a dataset that includes new relation annotations on 400 peer-reviews obtained from the OpenReview platform. Along with four other datasets, we further investigate data-efficient learning techniques:
- (i) Transfer learning (TL), which adapts models trained from a source domain to a new domain with the same task, or leverages large unlabeled in-domain data using self-supervised pre-training. Our experiments outline the cases where TL is effective, which is especially the case when less labeled data is available in the target domain.
- (ii) Active learning (AL), which strategically selects informative samples in the new domain for human labeling. This process is done in multiple rounds, subject to an annotation budget.
We explore both model-based and model-independent strategies for the relation prediction task, showing that the model-independent methods achieve competitive performance, while requiring significantly fewer resources.
How does your research advance the state-of-the-art in the field of natural language processing?
Argumentation is a crucial skill in which we engage during various situations. A key step to enabling machine understanding of arguments is to identify the support and attack relations between individual propositions. Such argument diagrams can help discover the central theses and reasoning process, and subsequently allow AI systems to rapidly detect trends and categorize arguments for the end-user.
However, acquiring high-quality annotated data on argumentative relations is extremely costly, especially for data that requires domain expertise. Although prior efforts have created several datasets and models, there is no unified framework that adapts well across domains.
In this work, we propose a novel Transformer-based relation prediction model. Contrary to existing work that relies on features or has no access to long context, our model is context-aware and can be easily adapted to new domains.
We also release new relation annotations on academic peer reviews. Along with four existing datasets, we showcase the effectiveness of transfer learning and active learning, especially when labeled data is limited in the target domain.